Python で正規表現を使う基本的な例
ここでは Python における正規表現 (regular expression) の基本的な利用方法を説明します。
ここでは具体的に問題を考えて、Python での正規表現の使い方をみてみましょう。
正規表現とは?

航空機の便名を例にとって考えてみましょう。
空港でよく見かける航空機の便名は、「二桁の航空会社コード」と「4桁以内の数字のフライトナンバー」からできています。
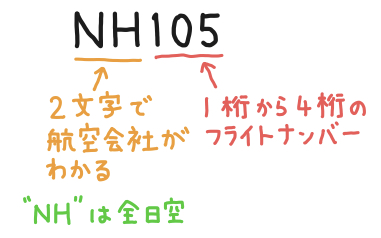
さて、ある文字列が渡された時にそれが、「航空機の便名」の形式であるかどうかチェックするにはどうしたら良いでしょうか。
そして、さらに文字列から「航空会社コード」と「フライトナンバー」を取り出すとしたら、どうすれば良いでしょうか。
正規表現を使うと、次のようなコードで簡単に、便名のフォーマットであるかチェックして、 さらに航空会社コードとフライトナンバーを抜き出すことができます。
import re
m = re.search(r'^([A-Z0-9]{2})(\d{1,4})$', 'NH105', re.I)
if m is None:
print('Not match')
else:
print(f'Airline: {m.group(1)}')
print(f'Flight : {m.group(2)}')この結果、次のような結果が出力されます。
Airline: NH
Flight : 105入力した文字列は NH105 でしたが、確かに最初の2文字 NH と、 フライトナンバーの数字 105 が取得できています。
上のコードの 2行目が、正規表現のパターンを表している箇所です。
なんと、この一行だけで、フォーマットのチェックや航空会社コードやフライトナンバーの抜き出しなど、全てを行っているのです。
ここで使っている、re.search() 関数の引数の意味は次の通りです。
re.search(パターン, 調べる文字列, [フラグ])
今回の場合は次のようになります。
- パターン: r'^([A-Z0-9]{2})(\d{1,4})$'
- 調べる文字列: 'NH105'
- フラグ: re.I
正規表現のパターンの意味
それでは、今回使ったパターンの意味を読み解いていきましょう。
r'^([A-Z0-9]{2})(\d{1,4})$'パターンについては、バックスラッシュ (\) などの特殊文字をよく使うので、文字列の前に r を付けて生文字列 (raw string) にしてます。
<パターンの前半部分の意味>
まずは、前半分の ^([A-Z0-9]{2}) の部分を取りあげます。
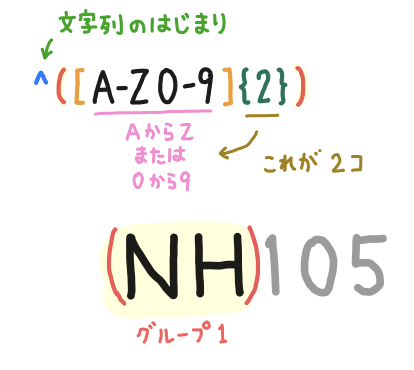
最初の ^ は「文字列の始まり」の意味です。
[A-Z0-9] は 「AからZ または 0から9」という意味です。それに続く {2} は「直前のパターンが2個」の意味です。
[A-Z0-9]{2} は丸括弧 () に囲まれています。ひとつめの丸括弧は「これをグループ 1 とする」という意味です。
以上から、^([A-Z0-9]{2}) というパターンは、 「文字列の始まりから、『AからZまたは0から9』の文字が 2 個続いた箇所をグループ 1 にする」という意味になります。
今調べている文字列は NH105 でしたから確かに、先頭の 2 文字は "NH" であり、パターンに当てはまります。このため、グループ 1 に "NH" が取り込まれます。
<パターンの後半部分の意味>
では、パターンの後半部分 (\d{1,4})$ を見てみましょう。

\d は「0から9」という意味です。それに続く {1,4} は「直前のパターンが1から4個」の意味です。
\d{1,4} は丸括弧 () に囲まれています。ふたつめの丸括弧なので「これをグループ 2 とする」という意味になります。
そして、直後にある $ は「文字列の終わり」の意味です。
以上から、後半に出てきた (\d{1,4})$ というパターンは、 「文字列の終わりの直前の、『0から9』の文字が 1〜4個続いた箇所をグループ 2 にする」 という意味になります。
今調べている文字列は NH105 でしたから確かに、文字列の終わりの 3 文字は "105" であり、パターンに当てはまります。このため、グループ 2 に "105" が取り込まれます。
<パターン全体の意味>
もう一度、全体をみてみましょう。(生文字列を表す r と '' を除いています)
^([A-Z0-9]{2})(\d{1,4})$パターンの前半部分と後半部分のパターンは、連続していますから、上の条件を続けて満たす必要があります。
つまりこのパターンは、「文字列の始まりから『AからZまたは0から9』の文字が 2 個続いたら、これをグループ 1 とし、 さらに続けて、『0から9』の文字が1〜4個続いて文字列が終わったら、それをグループ 2 とする」というパターンであったということになります。
航空会社コードの「二桁とも数字である場合を排除」する場合
実際の航空会社コード (IATA コード) では、 1U (Google/ITA) や Q5 (40-Mile Air) のように数字を含むコードはありますが、二桁共に数字のコードはありません。
「二桁共に数字を排除する」という条件も正規表現のパターンに入れるなら、次のようにします。
r'^(?!\d{2})([A-Z0-9]{2})(\d{1,4})$'(?!) というのはネガティブルックアヘッド (negative lookahead) といって、「次にこれがあったらマッチしない」という条件を指定するものです。この場合、 (?!\d{2}) とすることで、「次に2文字とも数字があったらマッチしない」という条件を付与していることになります。
re.search() 関数のフラグ
re.search() の第三引数にはフラグを指定します。何も指定しなくても構いません。
今回は re.I というフラグを指定しているので、「大文字小文字を区別しない」 という意味を付け加えたことになります。 re.I は re.IGNORECASE の省略形です。
re.search() 関数の戻り値
match 関数はマッチした場合、マッチオブジェクト (MatchObject) を返します。マッチしなかったときは None を返します。
そのため match 関数を読んだあと、その戻り値を is None としてチェックして、パターンがマッチしたか確認しています。
マッチオブジェクト m の group() 関数を使うと、グループとして取り込んだ文字列を取得できます。「グループ 1」として取り込んだ文字列は m.group(1)、 グループ 2 として取り込んだ文字列は m.group(2) で取得できます。
尚、 m.group(0) には、パターンがマッチした文字列全体がセットされます。今回の場合、 m.group(0) は NH105 です。
re.search() 関数と re.match() 関数の違い
re モジュールには基本的なパターンマッチ用関数として、 re.search() 関数の他、 re.match() 関数というのもあります。
re.search() 関数とre.match() 関数は、何が違うのでしょうか?
re.match() は文字列の先頭からパターンをチェックすることを前提としています。 つまり、パターンとして ^ を指定しなくても、それを含んでいることになります。
その他の違いとして、 re.MULTILINEフラグを指定して複数行モードでパターンマッチングをした時に、 re.search() 関数内の ^ パターンは行毎の先頭部分にマッチしますが、 re.match() 関数ではあくまでも文字列の始まりのみにマッチします。
今回のサンプルのまとめ
もう一度、元のコードを見てみましょう。
import re
m = re.search(r'^([A-Z0-9]{2})(\d{1,4})$', 'NH105', re.I)
if m is None:
print('Not match')
else:
print(f'Airline: {m.group(1)}')
print(f'Flight : {m.group(2)}')今回出てきたパターンは次の通りです。
- [A-Z0-9] : A から Z または 0 から 9
- \d : 0 から 9
- ^ : 文字列の始まり
- $ : 文字列の終わり
- {4} : 長さ4
- {1,4} : 長さ 1 から 4 の間
- () でグループに取り込む
- re.I フラグで大文字小文字区別しない
これを Python の re モジュールの re.search() 関数でマッチさせ、マッチした場合はマッチオブジェクトが返り、マッチしなかった場合は None が返ります。
re.match() 関数は re.search() 関数と似た動作をしますが、re.match() 関数ではいつも文字列の先頭からのパターンマッチを行います。
正規表現のパターンは今回登場したもの以外にも、たくさん書き方があります。全部覚えるのは大変ですし、無理に丸暗記する必要もないと思います。
正規表現の基本的な事柄を押さえておくだけでも、だいぶプログラミングは簡単になると思います。
以上、Python の正規表現の基本的な使い方を説明しました。