lxml の基本的な使用方法
lxml は Python で使える XML や HTML ファイルの処理用のライブラリです。 機能が充実している上にとても使いやすいので人気があります。
この記事では lxml の基本的な使用方法について説明します。
インストール
lxml は pip で簡単にインストールできます。
$ pip install lxml
個別の環境を作成するにはvirtualenv を利用するのが便利です。
テスト用のファイルの準備
ここでは次のサンプル XML ファイル usa-states.xml を利用して、lxml ライブラリの基本的な使用方法を説明します。
<?xml version="1.0"?>
<states>
<state code="CA">
<name>California</name>
<capital>Sacramento</capital>
</state>
<state code="HI">
<name>Hawaii</name>
<capital>Honolulu</capital>
</state>
<state code="TX">
<name>Texas</name>
<capital>Austin</capital>
</state>
</states>
XML ファイルの読み込み
lxml を利用するには lxml パッケージから、etree をインポートします。
parse メソッドで XML ファイル名を指定すると、XML ファイルが読み込まれて、XML ノードのツリー構造が自動的に認識されます。
次のコードでは上記のサンプルファイル usa-states.xml を読み込み、ルートノードの要素名を出力しています。また、ツリー全体をダンプしています。
from lxml import etree
tree = etree.parse('usa-states.xml')
root = tree.getroot()
print( 'root tag = %s' % root.tag )
print( etree.tostring(tree).decode() )
実行結果は次の通りです。
root tag = states
<states>
<state code="CA">
<name>California</name>
<capital>Sacramento</capital>
</state>
<state code="HI">
<name>Hawaii</name>
<capital>Honolulu</capital>
</state>
<state code="TX">
<name>Texas</name>
<capital>Austin</capital>
</state>
</states>
iter による XML ノードの選択
次に state という名前の XML 要素を読み込み、その属性と子要素を列挙してみましょう。
まず ElementTree XML API に近い形として、ノードの iter メソッドで要素を列挙してみます。
from lxml import etree
tree = etree.parse('usa-states.xml')
root = tree.getroot()
print( '== state ==')
for state in root.iter('state'):
print( '*** %s' % state.attrib )
print( 'attr=[%s]' % state.attrib['code'] )
for child in state:
print( ' tag=[%s] text=[%s]' % (child.tag, child.text) )
== state ==
*** {'code': 'CA'}
attr=[CA]
tag=[name] text=[California]
tag=[capital] text=[Sacramento]
*** {'code': 'HI'}
attr=[HI]
tag=[name] text=[Hawaii]
tag=[capital] text=[Honolulu]
*** {'code': 'TX'}
attr=[TX]
tag=[name] text=[Texas]
tag=[capital] text=[Austin]
確かに XML 要素と属性、及び、子要素が認識されていますね。
lxml では選択された要素はリストと同様に扱えるようになっています。 また、それぞれ属性 (のリスト) は .attrib、 文字は .text、要素名は .tag としてそれぞれ取得できます。
XPath
XPath とは? 〜 XPath を利用する動機
通常、XML を処理する際には XML 要素の階層(親子関係)を意識しつつノードを読み込むことが重要になります。
しかし、iter メソッドでは、ルート要素直下の state 要素も、 下の階層にある要素も同様に取得します。
実際の XML データを解析する際には、ノードの親子関係自体が貴重な情報です。 XML ファイル全体から同じ名前のノードを一律に取得すると、XML ファイルの内容の解釈を誤る場合があります。
例えば、XML に次のように同じ名前のノードを含む場合、iter メソッドでは、ルート要素直下の state 要素も、 下の階層にある要素も同様に取得してしまいます。
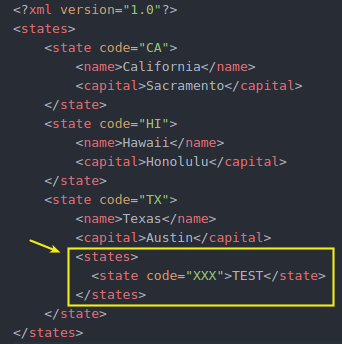
このデータに対する上記コードの実行結果は次の通り。
== state ==
*** {'code': 'CA'}
attr=[CA]
... 省略
tag=[capital] text=[Austin]
tag=[states] text=[
]
*** {'code': 'XXX'}
attr=[XXX]
そのため、実際には iter メソッド的な動きは使いにくいものです。
そこで、XPath を使った要素の選択が重要です。lxml ライブラリはこの点で優れています。
XPath の利用
lxml で xpath を使って、XML 要素を選択する方法をいくつかみてみましょう。
まず states > state という階層にある state 要素を取得する場合は次のようにします。
from lxml import etree
tree = etree.parse('usa-states.xml')
root = tree.getroot()
states = tree.xpath('/states/state')
if len(states):
for state in states:
print( state.attrib )
{'code': 'CA'}
{'code': 'HI'}
{'code': 'TX'}
もし iter のように階層を意識しない場合は次のように XPath を // からはじめます。
...
states = tree.xpath('//state')
if len(states):
for state in states:
print( state.attrib )
属性として code="HI" をもち、states 以下にある state 要素を選択するには次のようにします。
states = tree.xpath('/states/state[@code="HI"]')
データの更新
属性や文字列を変更するには、そのまま値を入れ直すだけで OK です。
次の例では取得したノード内に新たに attr1 属性を作り、それに対して Hello! という文字を割り当てています。
from lxml import etree
tree = etree.parse('usa-states.xml')
root = tree.getroot()
states = tree.xpath('//state[@code="TX"]')
if len(states):
for state in states:
state.attrib['attr1'] = 'Hello!'
print( state.attrib )
print( etree.tostring(tree).decode() )
{'code': 'TX', 'attr1': 'Hello!'}
<states>
<state code="CA">
<name>California</name>
<capital>Sacramento</capital>
</state>
<state code="HI">
<name>Hawaii</name>
<capital>Honolulu</capital>
</state>
<state code="TX" attr1="Hello!">
<name>Texas</name>
<capital>Austin</capital>
</state>
</states>
ファイルへの保存
ツリー構造をそのままファイルに書き出し保存するには、write メソッドを呼びます。
from lxml import etree
tree = etree.parse('usa-states.xml')
root = tree.getroot()
states = tree.xpath('//state[@code="TX"]')
if len(states):
for state in states:
state.attrib['attr1'] = 'Hello!'
tree.write(
'lxml-output.xml',
pretty_print = True,
xml_declaration = True,
encoding = "utf-8" )
エンコーディングや XML 宣言の有無などもここでオプションとして指定できます。
以上、lxml ライブラリの基本的な使用方法を説明しました。