Python の filter() 関数
Python の filter() 関数とは
filter(f1, iterable) 関数は Python のビルトイン関数です。何もモジュールをインポートすることなく使うことができます。
filter(f1, iterable) 関数は、第二引数に渡したコレクション (iterable) オブジェクトの要素を、 第一引数の関数 f1 にひとつずつ渡して評価し、True となる要素だけからなるコレクションを作成します。
Python の filter() 関数を使う例
具体例として、「[7, 4, 2, 10] というリストから、5 より大きい数字を抜き出したリストを作る」 ことを考えてみましょう。
この場合、第一引数の関数として、 「x > 5 なら True。それ以外は False」 とする関数を渡します。 第二引数にリスト [7,4,2,10] を渡します。
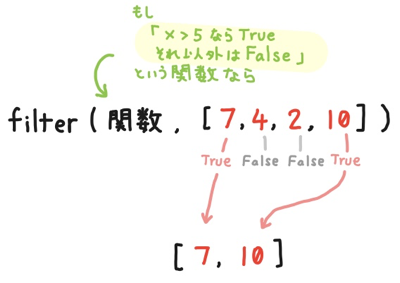
filter() 関数はリストの要素をひとつずつ評価して、リストの要素 7 と 10 のときに True となります。 その結果、 [7, 10] というコレクションが得られます。(リストにするには list() 関数を呼びます。)
この例を実際に Python のコードで書くと次のようになります。
def my_func(x):
return x > 5
my_list = list(filter(my_func, [7, 4, 2, 10]))
print(my_list) # [7, 10]関数は lambda 式を使うこともできます。lambda 式を使って書き直すと、次のようになります。
my_list = list(filter(lambda x: x > 5, [7, 4, 2, 10]))
print(my_list) # [7, 10]
lambda 式 (ラムダ式) は lambda (引数): (戻り値) という形で書きます。 詳しくは「Python の lambda 式」をみてください。
Python の filter() と map() を組み合わせて使う
もうひとつ実践的な例を挙げます。
従業員 (employees) のデータが、ディクショナリのリストとして与えられているとします。それぞれの従業員の名前 (name) と年齢 (age) のリストです。
employees = [
{"name": "John", "age": 21},
{"name": "Kevin", "age": 45},
{"name": "Amy", "age": 21},
{"name": "Ryan", "age": 30}
]この中から、年齢 (age) が 25 より大きいデータだけを取り出してみましょう。
そのために filter() 関数を利用します。
リストの中身はディクショナリ型なので、ラムダ式で x["age"] として年齢を取り出して、評価します。
result = filter(lambda x: x["age"] > 25, employees)
print(list(result))
# [{'name': 'Kevin', 'age': 45}, {'name': 'Ryan', 'age': 30}]
さらにもし、フィルターしたディクショナリから name だけを抜き出したい場合には、どうしたら良いでしょうか。
この場合、filter() 関数の実行後に、その結果に対して map() 関数を使います。
map() 関数については「Python の map() 関数」も参考にしてください。
result = map(lambda x: x["name"], (filter(lambda x: x["age"] > 25, employees)))
print(list(result))
# ['Kevin', 'Ryan']1 ステップ毎に異なる行に書けば当たり前とも言える操作ですが、実際にはまとめて書いてしまうことが多いものです。
以上、Python のビルトイン関数の一つである filter() 関数の説明と、 filter() 関数を使う具体例を紹介しました。